

I got this question the other day: “What does the BGP Next-Hop-Self command actually do?”
It is a great question that I tried to answer in a brief description without success, and actually repeated my answer several times. It was clear to me that my answer was not being understood in terms of a process or updating routing tables. I ended up wanting to diagram the answer, and then realized I needed a before and after the use of the command.
So the truth is that the answer cannot de stated in a simple one or two sentence response that makes sense to everyone. So here is a more detailed explanation.
Let’s begin with a base network topology like this:
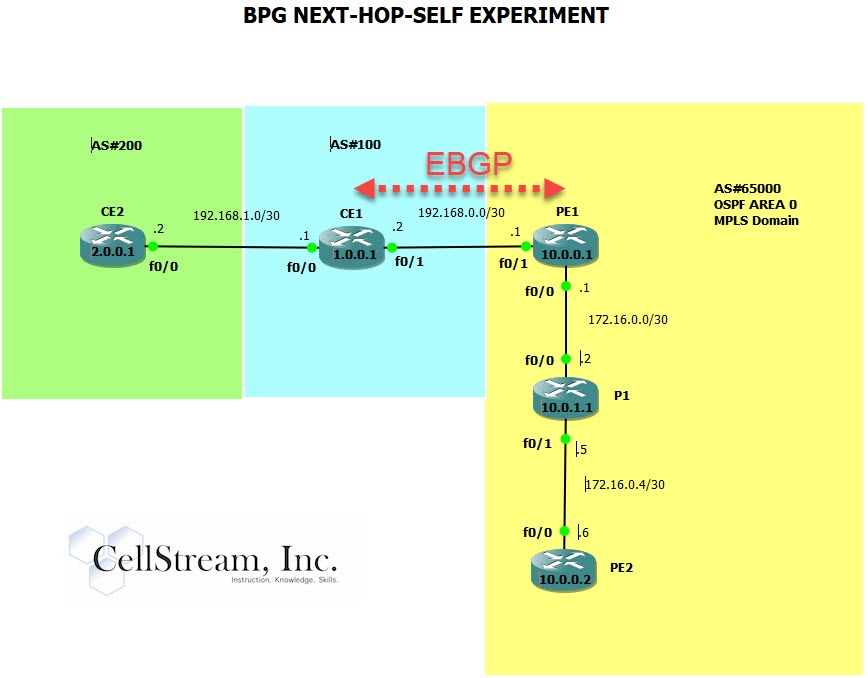
Let’s look at the Routing Table of CE1 with a focus on the loopback address of PE1 which is 10.0.0.1:
We can see this has been received by BGP (marked with a B) and it can be reached via the interface address 192.168.0.1.
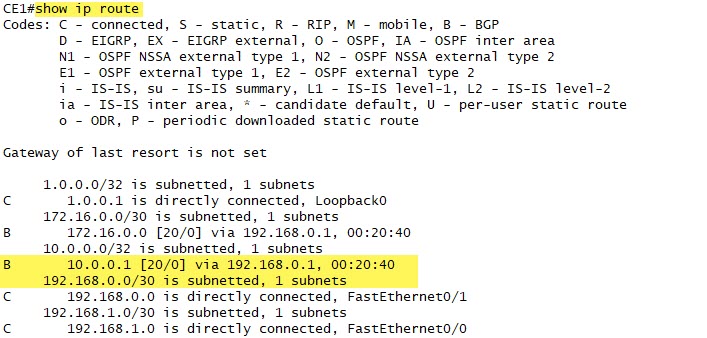
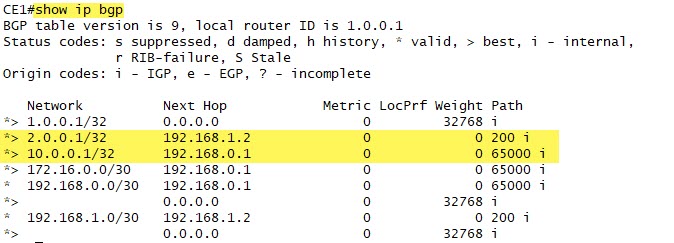
Now let’s look more specifically at the BGP database in CE1, again focused on the 10.0.0.1 destination:
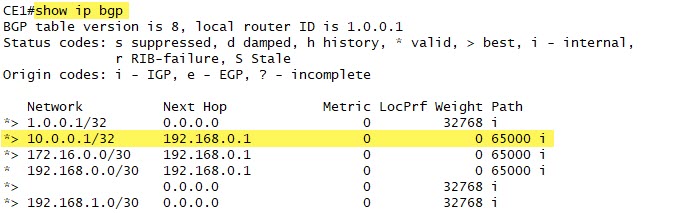
This is clearly an EBGP neighbor in AS65001 and we see the Next Hop attribute is 192.168.0.1.
What about PE1? Let’s look at its BGP table:
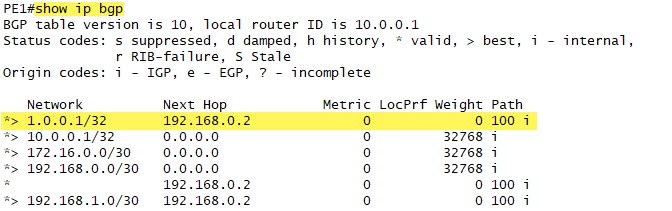
This all looks exactly as we would expect.
The next hop attricute is a well known and mandatory attribute communicated between BGP peers and defined in RFC4271 as follows:

I think the key term is ‘should’. It certainly has in our example so far.
Let’s see if we can make this go all wrong.
First, let’s modify our network a little. CE2 has now entered the control plane as an EBGP neighbor to CE1:
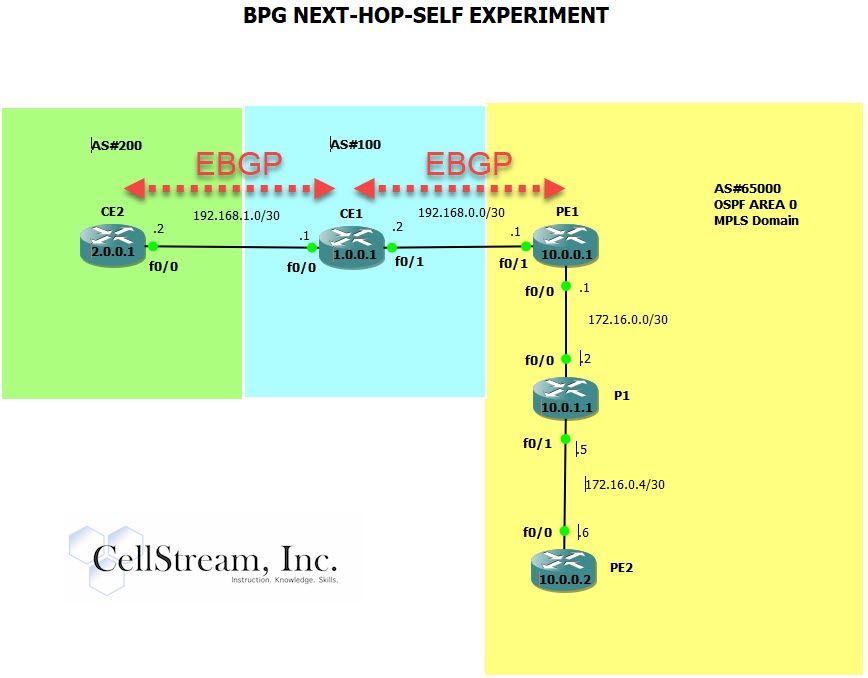
Are there any next ho issues?
If we examine the CE1 BGP table again, we see that the CE2 loopback of 2.0.0.1 has been added with it’s appropriate next hop:
What about PE1?
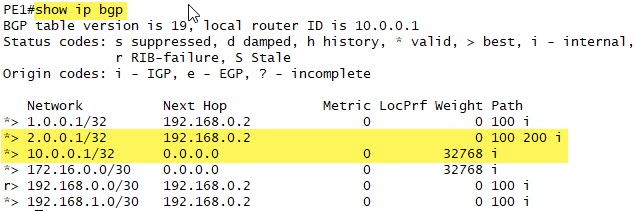
We see that the 2.0.0.1 route has been added and the next hop is listed correctly as being the interface to CE1 with the AS Path being 100, then 200.
So far all is well. By default, routes advertised to EBGP neighbors will have Next-Hop attribute changed to EBGP session’s source IP address. Therefore you don’t have to do anything. More importantly, there is no point in configuring ‘next-hop self’ on EBGP sessions, everything is done automatically.
As we will see, this is not the case with inter-AS BGP operations. So let’s modify the network by bringing in PE2 as an IBGP neighbor to PE1:
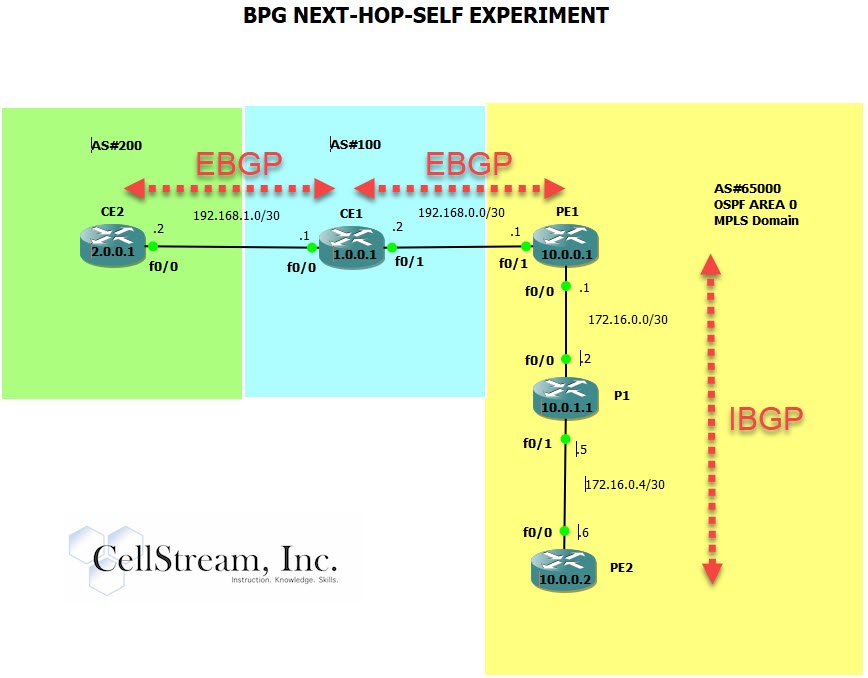
Alright. Does PE2 receive the BGP routes? Yes:
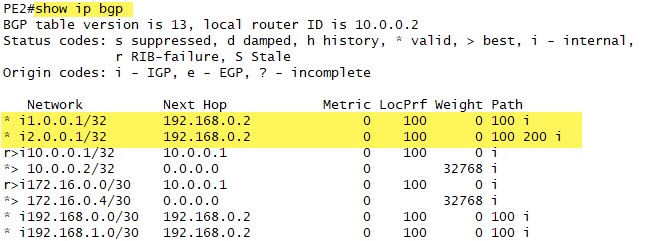
And we see the next hops for CE1 and CE2 are 192.168.0.2.
But there is a problem. If we try to ping 2.0.0.1 or 1.0.0.1 we get no data plane success:
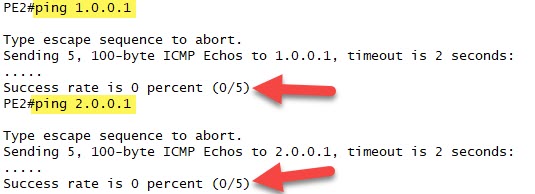
Why?
Well to the casual observer, everything seems fine in the routing table and the BGP table. But closer examination of one of the routes reveals an issue:
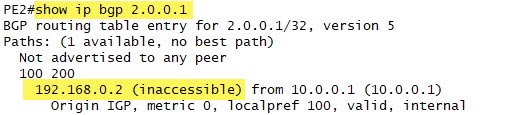
So this is where the Next-Hop-Self command can come to the rescue. We will add this to the PE1 config:

Now let’s go back and look at PE2 and we see that the next hop has changed. It was 192.168.0.2 previously. It is now 10.0.0.1, which PE2 knows how to get to, and the result is successful pings:
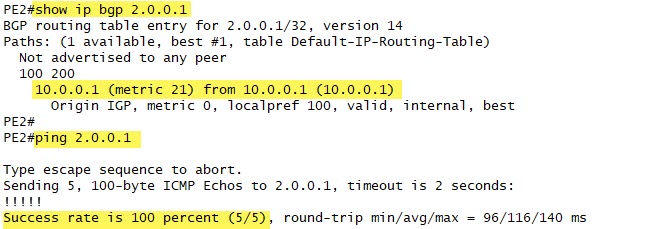
Now there are other ways to solve this issue, like adding network commands in order to inject/advertise the 192.168.0.2 route into AS#65000, but that can convolute routing tables with possible customer routes. Plus if we had configured a VRF for the customer, everything to the left of PE1 would be in the VRF table, and again, all the routes would appear in a matching VRF in PE2, but they may not be actually reachable if the next hop is inaccessible. In relatively simple MPLS L3VPN networks this is usually not an issue, but some best practices simply add this next-hop-self configuration to L3VPN PE configurations for future-proofing their network management.
So when troubleshooting EBGP and IBGP networks, be sure to look carefully at the next hop attribute of BGP. This is particularly true in BGP confederation networks, but also simple networks like the one we used above. This is also true in networks with Route Reflectors, though Route Reflectors must not change Next-Hop attribute for routers that are being reflected. If you don’t follow this principle rule, you will end up sending data traffic to/through the Route-Reflectors which is often not desirable, as Route-Reflectors in many networks are only used for Control Plane, not Data Plane and might not have capacity to forward traffic.